主要的笔记内容针对于C++相关的内容,主要针对的课程为Stanford CS106L (2020)的笔记,主要为后面的xv6写的前置笔记知识
Lecture 1: Streams I
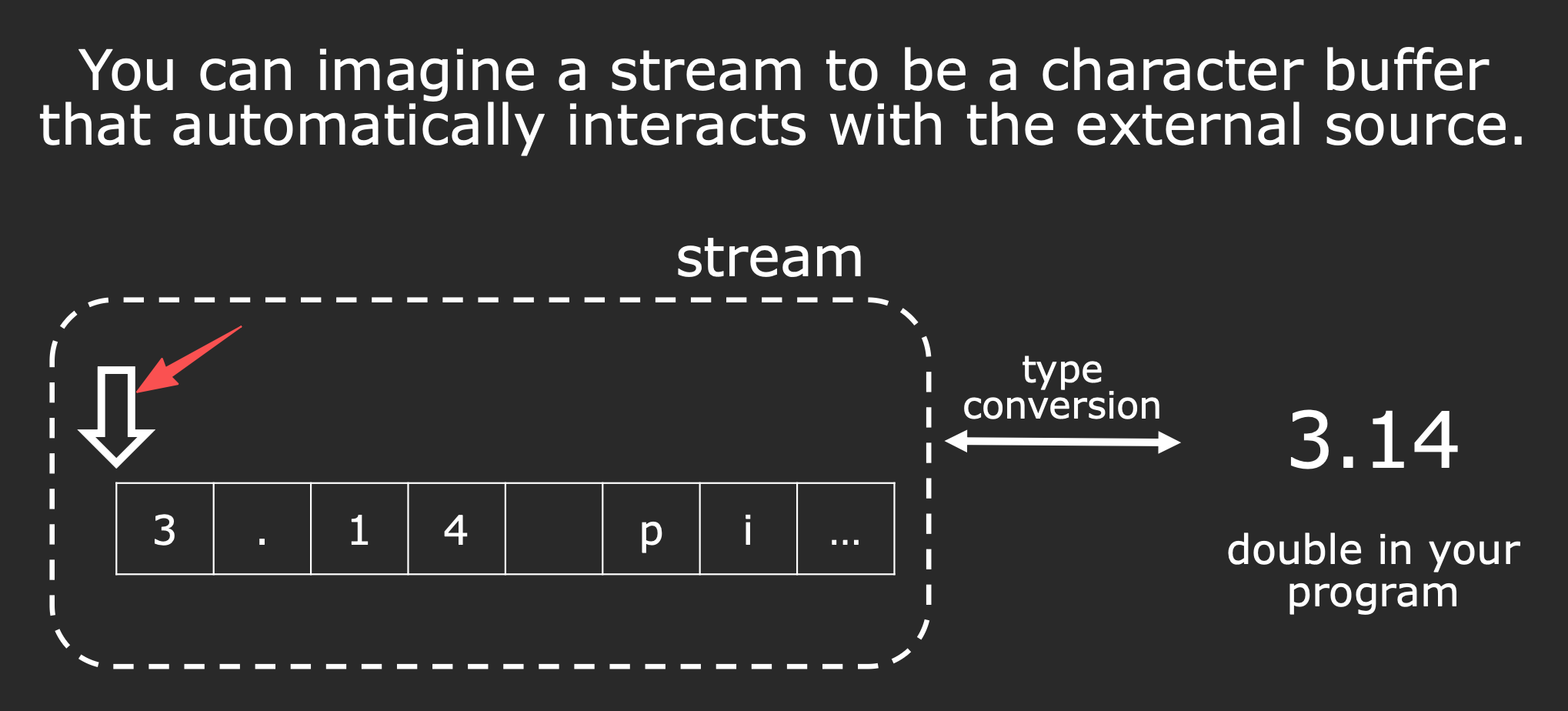
Streams 主要的作用就是:外部设备 ↔ (字符缓冲区)stream ↔ 你的变量(double、int、struct)
stringstream
std::istringstream: 输入字符串流(从string中按类型提取)std::ostringstream: 输出字符串流(往里面放入各种类型,得到string类型)std::stringstream: 既能读又能写
#include <iostream>
#include <sstream>
int main()
{
// “16.9 Ounces”, pos at front
std::istringstream iss("16.9 Ounces");
double value;
std::string unit;
iss >> value >> unit;
std::cout << "Value: " << value << ", Unit: " << unit << std::endl;
return 0;
}
// Value: 16.9, Unit: Ounces
上面的例子可以看到输入字符串流中的iss -> 16.9 Ounces后面根据类型进行分类,因为中间遇见了空格进行了两个位置进行分割
// “Ito En Green Tea ”, pos at front
std::ostringstream oss("Ito En Green Tea ");
oss << 16.9 << " Ounce";
std::cout << oss.str() << std::endl;
// 16.9 Ounceen Tea
上面的例子中的输出字符串流,指针进行因为是在字符串的最开始的位置开始的,所以内容会进行覆盖,这里就和PPT中的一个位置是一样的
如果想从字符串的最后面的位置开始进行拼接,可以使用方式ate或者直接使用+
// “Ito En Green Tea ”, pos at back
std::ostringstream oss("Ito En Green Tea ", std::stringstream::ate);
oss << 16.9 << " Ounce";
std::cout << oss.str() << std::endl;
std::string valuestr = "16.9";
std::string result = "Ito En Green Tea " + valuestr + " Ounce";
std::cout << result << std::endl;
//Ito En Green Tea 16.9 Ounce
//Ito En Green Tea 16.9 Ounce
stringstream formatted i/o(» / «)
<<:把变量转成字符,用于将数据推送到流对象中
>>:从缓冲区读取下一个 token,按变量类型解析

什么属于空白分隔符:空格,\t,\n等等可以被隔开的片段
//16.9 Ounces . -38271
std::cout << "Enter a string: ";
std::string input;
std::getline(std::cin, input);
std::istringstream iss(input);
double token1;
std::string token2;
char token3;
bool token4;
iss >> token1 >> token2 >> token3 >> token4;
std::cout << "Token 1: " << token1 << std::endl;
std::cout << "Token 2: " << token2 << std::endl;
std::cout << "Token 3: " << token3 << std::endl;
std::cout << "Token 4: " << token4 << std::endl;
//Enter a string: 16.9 Ounces . -38271
//Token 1: 16.9
//Token 2: Ounces
//Token 3: .
//Token 4: 1

#include <iostream>
#include <sstream>
int main()
{
//16.9 Ounces . -38271
std::cout << "Enter a string: ";
std::string input;
std::getline(std::cin, input);
std::istringstream iss(input);
int token1;
std::string token2;
char token3;
bool token4;
iss >> token1 >> token2 >> token3 >> token4;
std::cout << "Token 1: " << token1 << std::endl;
std::cout << "Token 2: " << token2 << std::endl;
std::cout << "Token 3: " << token3 << std::endl;
std::cout << "Token 4: " << token4 << std::endl;
return 0;
}
上面的例子中写入了cin的情况后面的lecture中会提到,正常的cin遇见空格就会停止读取,使用getline的话遇见的是\n,上面输入的是16.9 Ounces . -38271,那么通过istringstream把字符串包成一个输入流,去解析的时候
token1: 读int看到'1''6''.''9','.'对 int 无效,于是停在 ‘.’,结果token1 = 16token2: 跳过'.'前的空白,从'.'开始读string,string对'.'是合法字符,会读到"."(后面空白为止)token3: 跳过空白,读下一个char,得到'O'token4: 读取下一个那么就是U
stringstream positioning functions
oss.str():把当前缓冲区内容取成std::stringtellp()/seekp():输出位置指针(put pointer)tellg()/seekg():输入位置指针(get pointer)
#include <iostream>
#include <sstream>
int main()
{
std::ostringstream oss("ABCDEF");
oss.seekp(3);
oss << "Z";
auto pos = oss.tellp();
std::cout << "Position before writing Z: " << pos << " " << oss.str() << std::endl;
return 0;
}
stringToInteger and state bits
-
goodbit (G):一切正常,可以继续读写 -
failbit (F):上一次操作失败(比如类型不匹配),之后所有操作都会被卡死 -
eofbit (E):读到了缓冲区结尾(EOF) -
badbit (B):严重错误(IO 崩溃、设备坏了之类)
这里了解了一个好的编程方式,主要针对于if else可以直接转化为? :表达式,看起来简洁也好很多
void printStateBits(const istream& iss) {
cout << "State bits: ";
cout << (iss.good() ? "G" : "-");
cout << (iss.fail() ? "F" : "-");
cout << (iss.eof() ? "E" : "-");
cout << (iss.bad() ? "B" : "-");
cout << '\n';
}
对于要实现的stringToInteger如下所示:
#include <iostream>
#include <sstream>
int stringtoint(const std::string& str)
{
std::istringstream iss(str);
int value;
char remain;
if (!(iss >> value) || (iss >> remain)) {
throw std::domain_error("not a pure integer");
}
return value;
}
int main()
{
std::cout << "input str: ";
std::string input;
std::getline(std::cin, input);
int number = stringtoint(input);
std::cout << "Converted integer: " << number << std::endl;
return 0;
}
Lecture 2: Streams II
这个鬼调试搞了半天!因为cppdbg不太兼容console,导致会卡死很裂开,换成lldb可以了
{
"version": "0.2.0",
"configurations": [
{
"name": "codeLLDB",
"type": "lldb",
"request": "launch",
"program": "${fileDirname}/${fileBasenameNoExtension}",
"args": [],
"cwd": "${fileDirname}",
"preLaunchTask": "build c++",
"terminal": "integrated"
}
]
}
cout && cin && getline
cin:标准输入流(从终端/键盘方向来,但不是“直接从键盘读”)
cout:标准输出流(往终端打印,但不是“立刻显示”)
stream = buffer + position pointer + state bits 的抽象
cin在读我们键盘输入的内容,当我们的键盘回车后,系统会把这一行(包括 \n)交给cin的buffer
cin >> x并不是直接读键盘,而是buffer里面有内容就从buffer中读,buffer中没有内容才会卡住等带我们的输入,相当于只是从buffer中按照规则取字符,并移动读指针
cin >> 规则:
- 先
consume all whitespaces (空格、换行 \n、tab……),比如读取字符前面有这些的话会略过这些然后开始读 - 读取
token一般是到空白位置 - 对于
int/double这种基本类型,会尽可能读出一个变量所需的最大字符,从86.2提取int,会得到86,读指针停在小数点.
#include <iostream>
int main()
{
std::string name;
int age;
std::string response;
std::cin >> name;
std::cin >> age;
std::cout << name << age;
std::cin >> response;
return 0;
}
这个例子中假设我输入的是loxic null那么当age的位置的时候,想读int后,会先跳过空白读取的时候,读int失败,fall bit被打开,fallbit开了后,后面的cin都会失败
cout这里开始补充一下,比如我们代码是cout << "hello",这个并不能保证立刻出现在终端中,因为它可能先进入cout的输出缓冲区,这里补充一下输入(cin)操作都会 flush cout,endl以及std::flush都会强制刷新
#include <iostream>
int main()
{
std::cout << "Hello, World!";
std::flush(std::cout);
return 0;
}
对于cin的问题,cin会把整行输入放进buffer,但>>是按空白分token抽取,这里会很容易出现问题
这里引入了一个新的东西叫做getline,会读取到\n
#include <iostream>
#include <sstream>
int getInteger(const std::string& prompt = "integer: ",
const std::string& reprompt = "Please enter a valid ")
{
while(true)
{
std::cout << prompt;
std::string line; int value; char trash;
if(!std::getline(std::cin, line)) throw std::domain_error("[shortened]");
std::istringstream iss(line);
if(iss >> value && !(iss >> trash)) return value;
std::cout << reprompt;
}
}
int main()
{
std::cout << getInteger() << std::endl;
return 0;
}
>>和getline混用的话,这里要注意下,>>会把分隔符留在缓冲区内,而getline不会跳过最开始的空白区域,直接从当前的位置读取到\n
所以最好不用混着使用,如果要使用记得使用ignore()
#include <iostream>
#include <sstream>
int main()
{
std::istringstream iss("16.9 Ounces\n Pack of 12");
std::string str;
iss >> str;
std::string line;
std::getline(iss, line);
std::cout << "First word: " << str << std::endl;
std::cout << "Remaining line: " << line << std::endl;
return 0;
}
First word: 16.9
Remaining line: Ounces
输出结果是,会发现getline读取给line变量的时候会有空格,那么加上一个iss.ignore()去除第一个字符就可以把空格去掉
去看一下源码会知道很多
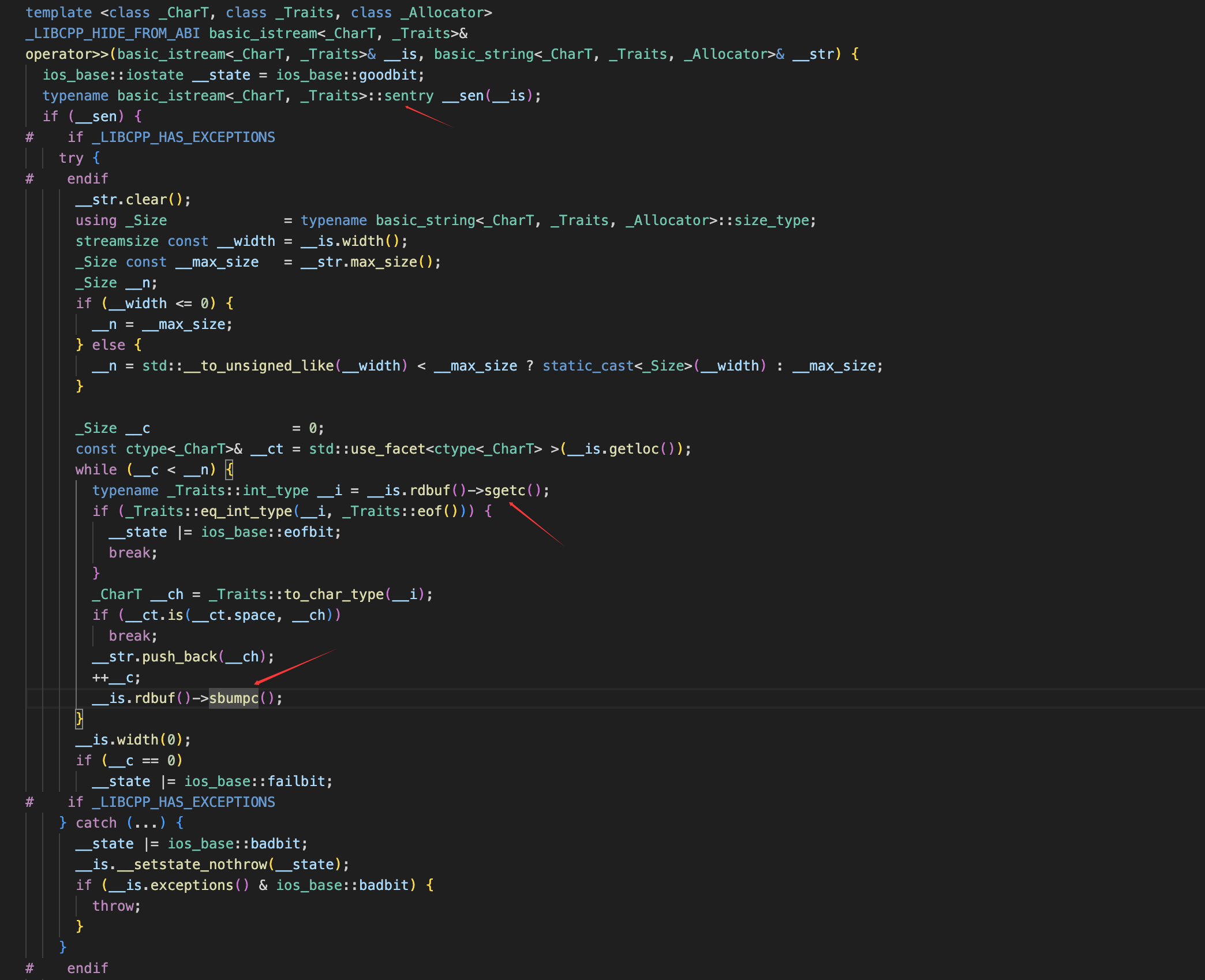
我们的输入会通过sentry来进行检查,这里会按照skipws跳过前导的空白
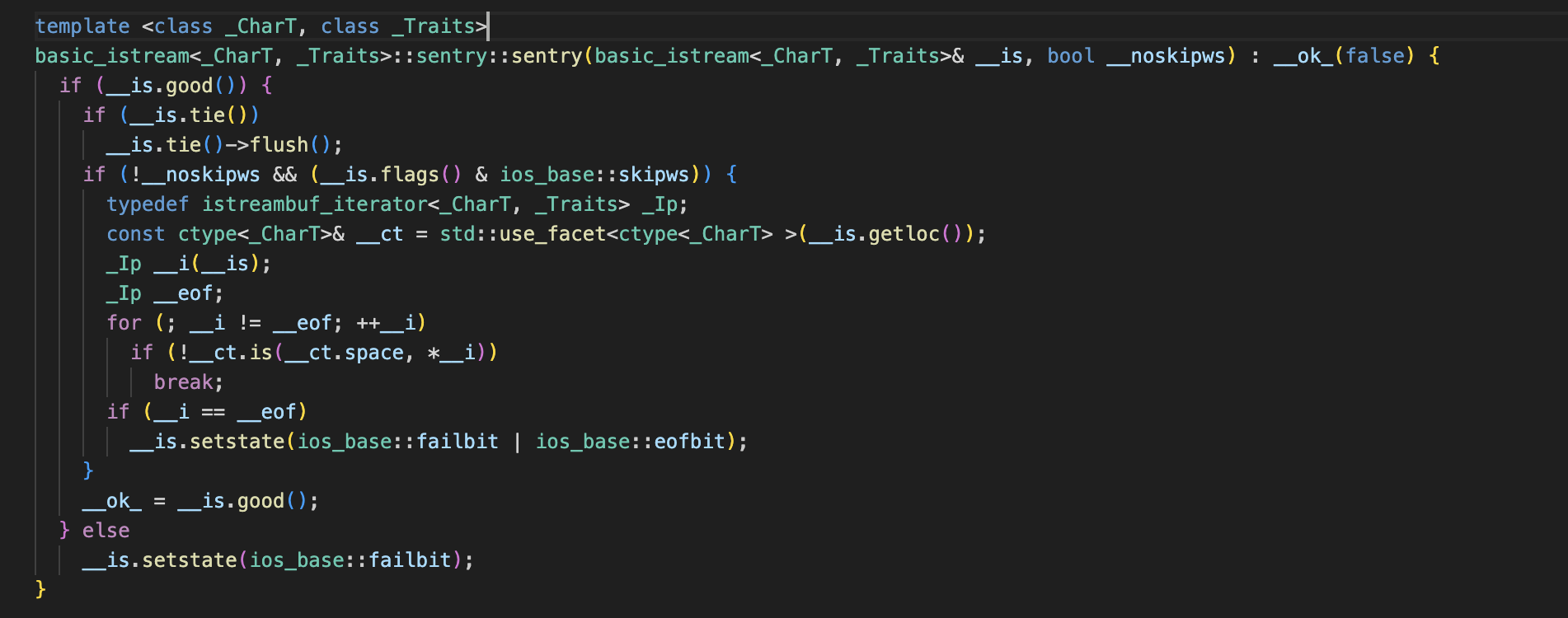
后面可以看到时sgetc取出来检查再进行sbumpc消费,所以到空格的时候检查没通过就不会消费,就会导致了分割的剩余
promptUserForFile challenge
写一个函数:提示用户输入文件名,尝试打开ifstream,如果打不开就reprompt,最后返回有效文件名
#include <iostream>
#include <sstream>
#include <fstream>
std::string promptUserForFile(std::ifstream& stream,
std::string prompt = "input your file name: ",
std::string reprompt = "false again, ")
{
std::string filename;
while(true)
{
std::cout << prompt;
if(!getline(std::cin,filename)) throw std::domain_error("input error");
stream.clear();
stream.open(filename);
if (stream.is_open()) {
return filename;
}
std::cout << reprompt;
}
}
int main()
{
std::ifstream file;
std::cout << promptUserForFile(file) << std::endl;
return 0;
}
modern c++ types
size_t
size_t 多用于索引/大小,无符号的整数,一般str.size()的返回类型通常是size_t(无符号),处理字符串的时候要小心如果字符串是空串的时候,一定要注意会不会出现无符号下溢的情况
// 有警告:signed 和 unsigned 比较
for (int i = 0; i < str.size(); ++i) { ... }
// 正确写法
for (size_t i = 0; i < str.size(); ++i) { ... }
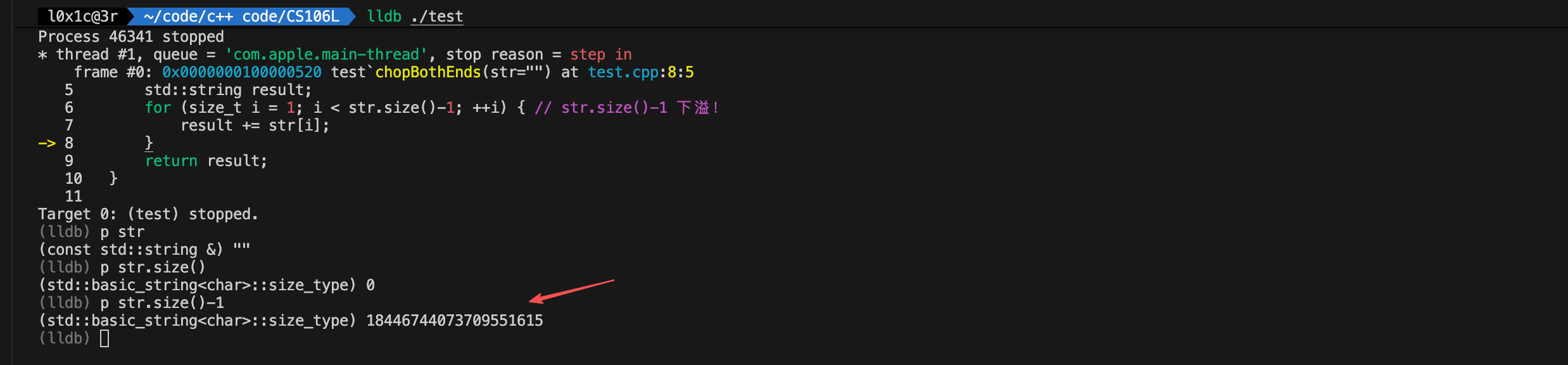
// 这个函数对空字符串会出bug!
string chopBothEnds(const string& str) {
for (size_t i = 1; i < str.size()-1; ++i) { // str.size()-1 下溢!
result += str[i];
}
}
trip:
如果想调试g++ -g -o xxx xxx.cpp
auto
让编译器自动推导类型:
auto x = 3.14; // double
auto name = "Avery"; // const char*(C字符串,不是string!)
auto name2 = string{"Avery"}; // string
auto copy = vec; // 完整拷贝
auto& ref = vec; // 引用,不拷贝
auto 会丢弃 const 和引用
const string& s = getStr();
auto x = s; // x 是 string(不是 const string&),会拷贝
const auto& y = s; // 这样才保留 const 引用
用 auto 的时机:
- 迭代器类型太长时
- 类型从上下文很明显时
- lambda 表达式(必须用 auto)
- 函数返回类型(尽量别用,可读性差)
pair && tuple
#include <iostream>
int main()
{
//两个值的组合
auto var1 = std::make_pair(1, 2);
//多个值的组合
auto var2 = std::make_tuple(3, 4, "hi", 5);
//取的方法
std::cout << "var1: " << var1.first << ", " << var1.second << std::endl;
std::cout << "var2: " << std::get<0>(var2) << ", " << std::get<1>(var2) << ", " << std::get<2>(var2) << ", " << std::get<3>(var2) << std::endl;
//拷贝
auto [a ,b] = var1;
std::cout << "a: " << a << ", b: " << b << std::endl;
//引用,为了防止被篡改,加上const
const auto& [x, y, z, w] = var2;
std::cout << "x: " << std::get<0>(var2) << std::endl;
return 0;
}
struct
#include <iostream>
struct Discount {
double discountFactor;
int expirationDate;
std::string nameOfDiscount;
};
int main()
{
auto coupon = Discount{0.9, 30, "New Years"}; // 统一初始化
coupon.discountFactor = 0.8;
auto [factor, date, name] = coupon; // 结构化绑定
std::cout << "Discount Factor: " << factor << std::endl;
std::cout << "Expiration Date: " << date << std::endl;
std::cout << "Name of Discount: " << name << std::endl;
}
References
string tea = "Ito-En";
string copy = tea; // copy 是独立副本
string& ref = tea; // ref 是 tea 的别名
tea[1] = 'a'; // tea 变了,ref 也变(因为是同一个东西)
copy[2] = 'b'; // 只改 copy,tea 不变
ref[3] = 'c'; // 改 ref 就是改 tea
永远不要返回局部变量的引用
char& bad(string& s) {
string local = s;
return local[0]; // 函数结束 local 被销毁,引用悬空!
}
类型转换
double d = 3.4;
int i = static_cast<int>(d); // 显式转换,i = 3
double d2 = 6; // 隐式提升,d2 = 6.0
Uniform Initialization
用 {} 来初始化几乎所有东西:
vector<int> vec{3, 1, 4, 1, 5, 9};
pair<int, int> p{1, 2};
return {min, max}; // 函数返回 pair 时
Lecture 3: Sequence Containers
what about STL
其实这节课,一直在介绍STL带来的方便和比较好的东西 STL:
- 容器(Containers) — 存放数据的"盒子"
- 迭代器(Iterators) — 用来遍历容器的"指针"
- 算法(Algorithms) — 对容器中的数据做操作(排序、查找等)
- 函子/仿函数(Functors) — 像函数一样使用的对象
- 适配器(Adaptors) — 在容器基础上做限制,形成新的数据结构(如栈、队列)
Sequence Containers
序列容器就是"按顺序存放元素"的容器
std::vector<T>
vector 就是一个可以自动扩容的数组, 可以把它想象成一个能自动变长的书架
std::vector<int> vec; //空vector
std::vector<int> vec(5); // 5个元素都是0
std::vector<int> vec(5, 10); // 5个元素都是10
std::vector<int> vec{1, 2, 3}; // 初始化列表
使用方法:
//创建
std::vector<int> vec(3); //空vector
vec = {1 ,3 ,7};
//vector添加元素只能添加在尾部
vec.push_back(9); //添加元素
std::cout << "第一个元素: " << vec.front() << std::endl; //访问第一个元素
std::cout << "最后一个元素: " << vec.back() << std::endl; //访问最后一个元素
std::cout << "下标访问: " << vec[0] << std::endl; //不检查越界
std::cout << "at访问: " << vec.at(0) << std::endl; //检查越界
//删除元素
vec.pop_back(); //删除最后一个元素
vec.erase(vec.begin()); //删除第一个元素
//其他使用方法
vec.clear(); //清空vector
vec.size(); //获取vector大小
vec.empty(); //检查vector是否为空
遍历vector的方法
vector<string> v = {"A", "B", "C"};
// 方式1:经典 for 循环(注意用 size_t)
for (size_t i = 0; i < v.size(); ++i) {
cout << v[i] << endl;
}
// 方式2:范围 for 循环(更简洁,推荐!)
for (string elem : v) {
cout << elem << endl;
}
// 方式3:引用遍历(避免拷贝,性能更好)
for (const string& elem : v) {
cout << elem << endl;
}
这是是推荐方式2和3的,告别之前c写法的方式1,对于2和3的区别就是string elem每次循环都会拷贝一个元素出来,而const string& elem 不是拷贝而是引用,那么如果vector里面元素很多的话,肯定是引用遍历速度是最快的
关于vector 的性能问题:push_front,课程里引入了一个问题,为什么vector里没有push_front
如果有push_front的话,假设如果有 n 个元素,就需要挪 n 次 → 时间复杂度 O(n),很慢(疯狂动物城里的闪电是吧!)
所以 vector 故意不提供 push_front,避免不小心写出低效的代码
std::deque<T>
所以引出了一个新的东西:叫做双端队列,解决了 vector 不能高效头部插入的问题
#include <iostream>
#include <deque>
int main()
{
std::deque<int> deq{1, 2, 3, 4, 5};
deq.push_back(6); // Adds 6 to the end of the deque
deq.push_front(0); // Adds 0 to the front of the deque
// 打印每个元素的地址,观察 deque 的分块内存布局
for(const auto& elem : deq) {
printf("Element: %d, Address: %p\n", elem, (void*)&elem);
}
deq.pop_back(); // Removes the last element (6)
deq.pop_front(); // Removes the first element (0)
std::cout << deq.front() << std::endl; // Outputs the first element (1)
std::cout << deq.back() << std::endl; // Outputs the last element (5)
return 0;
}
Element: 0, Address: 0x909000ffc
Element: 1, Address: 0x1008ce390
Element: 2, Address: 0x1008ce394
Element: 3, Address: 0x1008ce398
Element: 4, Address: 0x1008ce39c
Element: 5, Address: 0x1008ce3a0
Element: 6, Address: 0x1008ce3a4
deque 不是像 vector 那样用一整块连续内存,而是用多个小块内存,通过一个索引表把它们串起来
所以:头部插入时,只要在第一个块的前面加元素就行(或者分配一个新块),不需要移动其他元素 → O(1)
那么大部分时候用 vector 就够了,只有当你确实需要频繁在头部插入/删除时,才用 deque,deque对数据在中间位置的取值的效率并没有 vector 快
Container Adaptors
适配器是在已有容器上面加了使用限制,让它变成特定的数据结构
为什么要加限制: 因为限制能防止误用,让代码意图更清晰,当你看到代码用了 stack,立刻就知道这里是后进先出的逻辑
stack = deque + 限制(只允许 push_back 和 pop_back,只能看 top) queue = deque + 限制(只允许 push_back 和 pop_front)
stack
栈像盘子一样,满足的要求为只能从顶部放入,顶部取出,后进先出的原则
#include <iostream>
#include <stack>
int main()
{
std::stack<int> myStack;
myStack.push(1); // [1]
myStack.push(2); // [1, 2]
myStack.push(3); // [1, 2, 3]
std::cout << "Top element: " << myStack.top() << std::endl; // Output: 3
myStack.pop(); // [1, 2]
}
这个样子来说,底层实际上就是deque,但是只暴露了 push_back(push), pop_back(pop), back(top)的接口
queue
队列就像排队买奶茶,先来的先服务,先来先出
#include <iostream>
#include <queue>
int main()
{
std::queue<int> q;
q.push(1);
q.push(2);
q.push(3);
std::cout << "Front element: " << q.front() << std::endl; // Output: 1
std::cout << "Back element: " << q.back() << std::endl; // Output: 3
q.pop(); // Remove the front element (1)
}
本质上是对 deque 的封装:用 push_back 入队,用 pop_front出队
Lecture 4: Associative Containers
关联容器和序列容器最大的特点就是:关联容器没有"顺序"的概念,数据不是通过下标访问的,而是通过"键"(key)访问的
C++ 提供了4种关联容器:
- std::map<T1, T2> 有序的键值对(key-value),key 自动排序
- std::set<T> 有序的集合,只有 key,没有 value
- std::unordered_map<T1, T2> 无序的键值对,基于哈希表
- std::unordered_set<T> 无序的集合,基于哈希表
map 和 set是有序的:
- 内部用平衡二叉搜索树(通常是红黑树)实现
- key 必须支持 <(小于号)比较
- 遍历时按 key 排好序输出
- 适合需要范围查询的场景
unordered_map 和 unordered_set 是无序的:
- 内部用哈希表实现
- key 必须有对应的 hash 函数
- 单个元素的查找更快(平均 O(1) vs O(log n))
- 遍历顺序不确定
如果你只需要快速查找某个 key 是否存在或获取对应的 value,用 unordered 版本,如果需要有序遍历,用有序版本
std::map<T1, T2>
std::map<string, int> mymap;
// 插入
mymap["hello"] = 1;
// 两种访问方式的区别——非常重要!
mymap.at("hello"); // key 不存在时抛异常(安全)
mymap["hello"]; // key 不存在时会自动创建一个默认值的条目!(危险)
mymap[“newkey”] 如果 “newkey” 不存在,会自动插入一个 value 为默认值(int 的话是0)的键值对 mymap.count(key),返回0表示不存在,返回1表示存在
#include <iostream>
#include <map>
int main()
{
std::map<std::string, int> map_value;
map_value["one"] = 1;
map_value["rrr"] = 2;
std::cout << map_value.count("one") << std::endl;
map_value.erase("one");
std::map<std::string, int>::iterator i = map_value.begin();
while(i != map_value.end())
{
std::cout << i->first << i->second << std::endl;
++i;
}
return 0;
}
std::set<T>
set 本质上就是一个只有 key 没有 value 的 map 可以理解为:set 中的每个元素的"存在"就是它的 value(在就是 true,不在就是 false)
set 的方法和 map 基本一样,只是没有 [] 和 .at() 这种用key取value的操作
#include <iostream>
#include <set>
int main()
{
std::set<int> set_value;
set_value.insert(1);
set_value.insert(2);
set_value.insert(3);
std::cout << set_value.count(3) << std::endl;
set_value.erase(3);
std::cout << set_value.count(3) << std::endl;
return 0;
}
Iterators
为什么要有迭代器,序列容器可以用 for(int i = 0; i < size; i++) 来遍历,但关联容器没有下标,没有"第几个"的概念,怎么遍历,可以使用迭代器,迭代器就像一个"指针",它指向容器中的某个元素,可以把它想象成一个书签——它告诉你当前在哪个位置
迭代器把非线性的集合(比如树结构的 set)变成一个可以线性遍历的序列
创建迭代器:
set<int>::iterator iter = mySet.begin(); // 指向"第一个"元素
解引用:
cout << *iter << endl; // 用 * 号取出迭代器指向的值
推进(前进到下一个元素):
++iter; // 向前移动一步
比较(判断是否结束):
if (iter == mySet.end()) {
// 已经遍历完了
}
set<int>::iterator iter;
for (iter = mySet.begin(); iter != mySet.end(); ++iter) {
cout << *iter << endl;
}
mySet.end() 指向的是最后一个元素的后面一个位置(past-the-end),不是最后一个元素本身
迭代器map 和 set的区别就是,map 迭代器是一个 std::pair的结构
#include <iostream>
#include <map>
#include <set>
int main()
{
std::map<int, std::set<int>> myMap;
myMap[1].insert(10);
myMap[1].insert(20);
myMap[2].insert(30);
std::map<int, std::set<int>>::iterator it = myMap.begin();
std::set<int>::iterator setIt;
while (it != myMap.end())
{
std::cout << "Key: " << it->first << " Values: ";
for (setIt = it->second.begin(); setIt != it->second.end(); ++setIt)
{
std::cout << *setIt << " ";
}
std::cout << std::endl;
++it;
}
return 0;
}